
Memory isn’t something that we have to worry about very much in PHP, as memory management is handled for us by the Zend engine. However, when it does become an issue it becomes a very big one - most PHP script are limited as to how much memory they can consume. While this makes a lot of sense for web processes, and is in general not a problem, when you have a lot of data to deal with it can make life difficult.
Information retrieval is definitely one of those areas that can quickly result in having too much data to deal with. Even a moderate document store in a company could be in the gigabytes, and once you start indexing the web all bets are off. These kind of collections are too big to index in RAM in just about any system, let along the 32MB or so memory_limit is commonly set to.
An example of a tricky problem that occurs is the sort on indexing documents. The indexing process is basically just extracting a series of document -> term pairs and inverting them to give a set of mappings of terms to all the documents that contain them. If this list of pairs fits in memory, or in the mem limit, there’s no problem - but if not it can be rather awkward. You don’t want to be constantly going back and forth to disk, but at the same time the very first and last documents you look at might contain a given term, and you can’t process all of them while keeping the list in memory.
One solution, which applies to any time you have a large number of items which need to be sorted, is to use the disk. Block based external sorting does just this, by breaking the problem down into a series of smaller sorts, then recombining the intermediate block files into one sorted result file.
Because only one block has to be kept in memory at any time, the memory requirements are a lot smaller. The final recombination step is handled by opening small read buffers on each block file, and a single write buffer on the output file, which again helps keep the memory requirements modest.
Below is an implementation of a block based external sort in PHP. It’s used by calling addTerm repeatedly with a document and term, then calling merge at the end to fill the final file. Note that we’re just storing a term count here, but it would be trivial to store a list of match positions to support phrase search for example.
<?php
class BlockBasedExternalSort {
private $block;
private $blockCount = 0;
private $blockSize;
private $fileDirectory;
private $outputFile;
private $blockIndex = 0;
private $mergedBlocks = 0;
private $queue;
public function __construct($outputFile, $directory = '/tmp', $blockSize = 100000) {
$this->outputFile = $outputFile;
$this->fileDirectory = $directory;
$this->blockSize = $blockSize;
}
public function addTerm($documentID, $termID) {
if(!isset($this->block[$termID][$documentID])) {
$this->block[$termID][$documentID] = 1;
} else {
$this->block[$termID][$documentID]++;
}
$this->blockCount++;
if($this->blockCount >= $this->blockSize) {
$this->writeBlock();
}
}
public function merge() {
for($i = 0; $i < $this->blockIndex; $i++) {
$reads[] = fopen($this->getBlockFile($i), 'r');
}
$write = fopen($this->outputFile, 'w');
$this->buildQueue($reads);
$lastTerm = 0;
$combinedPostings = array();
while(count($this->queue) > 0) {
list($termID, $postings) = $this->getLowest($reads);
$combinedPostings =
array_merge($combinedPostings, unserialize($postings));
if($termID != $lastTerm) {
ksort($combinedPostings);
$lastTerm = $termID;
fwrite($write, $termID . "\n" .
serialize($combinedPostings) . "\n");
unset($postings);
$combinedPostings = array();
}
}
foreach($reads as $read) {
fclose($read);
}
fclose($write);
for($i = 0; $i < $this->blockIndex; $i++) {
unlink($this->getBlockFile($i));
}
}
private function buildQueue($reads) {
// if in 5.3, a SplPriorityQueue would be lovely here
$this->queue = array();
foreach($reads as $fID => $read) {
$this->queue[$fID] = (int)fgets($read);
}
asort($this->queue);
}
private function getLowest($reads) {
list($fID, $termID) = each($this->queue);
$postings = fgets($reads[$fID]);
$id = fgets($reads[$fID]);
if($id === false) {
unset($this->queue[$fID]);
} else {
$this->queue[$fID] = (int)$id;
}
asort($this->queue);
reset($this->queue);
return array($termID, $postings);
}
private function writeBlock() {
$this->blockCount = 0;
ksort($this->block);
$fh = fopen($this->getBlockfile($this->blockIndex++), 'w');
foreach($this->block as $termID => $postings) {
// we could retrieve bytes written here
// which we could store in the dictionary
// for efficient lookup
fwrite($fh, $termID . "\n" . serialize($postings) . "\n");
}
unset($this->block);
fclose($fh);
}
private function getBlockFile($index) {
return $this->fileDirectory . '/index' . $index . '.idx';
}
}
?>Each document/term ID pair is added to a term -> documents mapping, and once the number of pairs in memory exceeds the block size (here set at 100,000) the block is sorted and written to disk, and the variable is unset to free the memory. The file is written as a series of pairs of lines, one line for the term ID, then one for the documents that contain it.
Once all documents are parsed the client calls merge, which opens read handles onto each block file and retrieves the term - which will be the lowest term ID in that file. The term ID and a reference to the file are added to a queue array which is sorted to put the lowest at the top. The loop then proceeds with the documents for the lowest termID being merged from all the blocks that contain it. After each posting list is processed from a file the next term ID is read, and the queue once again sorted to keep the blocks with the lowest terms first. Each time the lowest term ID changes the previously merged posting list is written to the output file.
The queue array here is acting as a scrubby priority queue, and for those using PHP 5.3 a better option might to use the SplPriorityQueue. This is based on the heap data structure in SPL, and is intended for exactly what we’re doing here - putting a prioritised, but unordered set of items in, and retrieving them by their priority. The priority in this case in the termID, with lower being higher priority.
The downside of this approach is that bouncing to disk takes time. Running a sort over a small collection with the code below took about 5 seconds. Replacing the external sort with an in-memory array and a sort took about 3 seconds.
<?php
$bbes = new BlockBasedExternalSort(dirname(__FILE__) . '/index.idx', '/tmp');
$dictionary = array();
$termCount = 1;
$docCount = 1;
foreach(glob('*.txt') as $file) {
$fileContents = file_get_contents($file);
preg_match_all('/[a-zA-z]+/', $fileContents, $matches);
unset($fileContents);
foreach($matches[0] as $match) {
$match = strtolower($match);
if(!isset($dictionary[$match])) {
$dictionary[$match] = $termCount++;
}
$bbes->addTerm($docCount, $dictionary[$match]);
}
unset($matches);
$docCount++;
}
$bbes->merge();
?>The big gain, however, is memory usage. Tracking the memory usage in MB of the process above and the version just writing to the in-memory array over the run shows the block based sort levels out much lower. There is a slight blip at the end for the merge, but this could probably be optimised down somewhat.
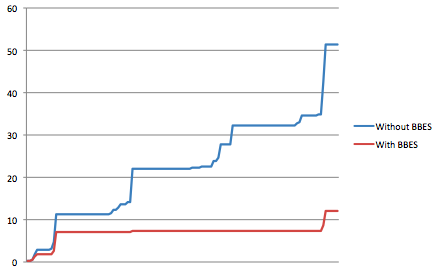
This is a nice result, and by tuning the block size you could tune the process to fit within whatever memory constraints were being applied.