
While organisationally many large financial companies were moving towards a more regulated message broker platform, via standards like JMS and AMQP, at the sharp end of market data distribution a different need was being uncovered. Problems were increasingly being hit with the fundamental concept of a broker in the first place. Having a centralised broker added an extra component in the middle of the architecture, and a distributed broker causes extra network hops and routing requirements. This could hurt performance, be a bottleneck, and also be a bit of a political battlefield - collaborating organisations would often have a message broker each, and hence be forced to deal with several extra steps.
In financial markets the challenge was the latency between the message being produced and it being received by the consumer, and latency was everywhere. Almost anything, it seems, could slow down the progress of messages across the network. There were batching algorithms in the network stack, such as Nagle’s algorithm in TCP or equivalents in network cards or routers. With these, what would have been multiple packets of information in a stream were combined into one to make better usage of bandwidth, at the cost of extra delay on some transmissions. There was latency introduced by CPU scheduling - there is a limit in granularity as to when a CPU will switch between one process and the next, and that cost limited the responsiveness of applications. Even the wire itself could be a problem: to maintain synchronisation between one host and another a clock is used to say when pulses can start and end for the encoded 1s and 0s of the transfer. Waiting for that clock to tick introduced transmission delay, particularly on older and slower networks.
A> Batch delivery is a tricky subject, as it often involves trading off performance in one domain (say, end-to-end latency) with performance in another (such as throughput on the network). Nagle’s Algorithm in TCP is one of the older attempts to add batching to a protocol. When using it, a sender will keep hold of outbound packets until either the previously sent data is acknowledged or a maximum size is hit, in which case all buffered messages will be sent. This works when there are lots of small packets being sent with quick replies (the canonical example being individual keypresses sent over a terminal application), but can easily start playing badly with more latency sensitive applications (one of the reasons it can be turned off with the TCP_NODELAY flag). A> A potentially conflicting change to TCP was introduced at around the same time as Nagle’s Algorithm, the Delayed Acknowledgment. This is basically the same idea, but batching up ACKs so that individual packet ACKs are not delivered until there are enough to send, or a timeout is hit (usually 500ms). The effect of running both is that you have a number of ACKs buffering at one end and packets buffering at the other, and only when one of the limit conditions is hit do you actually send data, introducing rather a lot of latency. The algorithms can also play badly with larger data, as the final packet or final ACK may end up being buffered rather than immediately sent, delaying the delivery of a reconstructed message that spanned multiple packets. A> That said, the general idea is a sound one, and the algorithm has been reimplemented at different layers by many vendors. Messaging is a natural fit - for example in a Pub/Sub case batching multiple published messages for the same topic into one can reduce the matching overhead, and when there are other full buffers batching up messages can lead to more efficient network usage and throughput. The benefits do tend to accord to how effective the “send” condition is - if a system sends as soon as it can, batching is usually not harmful to latency and just improves throughput during peaks.
One of the biggest bottlenecks though was the broker itself - and the extra hops involved could make any one of the previous latency issues worse. Moving messages from network to network generally involved going through a broker for each network, which gave further opportunities for any costs to appear. Often messages would be duplicated due to configuration or broker implementation. Work that involved many stages via the broker would incur needless copying: from the broker to worker A then back to the broker, then B and so on. Often the broker became required simply for part of its functionality, but ended up coupling the resulting app to the vagaries of the messaging system. For example, some systems may need to listen only to certain messages flowing locally - perhaps in and out of the same machine - but end up involving a broker primarily for the filtering functionality.
The broker can also provide a single point of failure - if it dies, no messaging can occur. Avoiding that requires a distribution method for creating highly available sets or clusters of brokers - which can add a lot of complexity to the system. In general, in many ways the broker was mixing the functionality it provided, adding a layer of messaging, but it also providing services that consumed those messages. That conflation of responsibilities cried out for separation, in the same way that the early packet network designers had separated TCP and IP to gain power in how the system was implemented.
Passing messages directly between producer and consumer, while being attractive because of the speed, seemed like a step backwards. Was it even necessary to use a messaging system at that point instead of a general network library? How do you maintain the benefits the broker brings, without incurring the costs of the performance impact? These ideas were explored by several companies, notably including Todd Montgomery at 29West, resulting in the LBM (Latency Busters Messaging) brokerless messaging system.
To make a messaging system brokerless there were several challenges that needed to be overcome. Brokers remove the need for services to know the location of the endpoints, and they allow consumers and producers to be totally asynchronous - there never needs to be a moment where both are online, as long as each is while the broker is. The brokerless solution didn’t throw away these benefits, but it distributed them. Brokerless messaging implemented each aspect of this functionality in separate components, and used a peer to peer style message passing library which handled the communication patterns between nodes.
Subsequently, the low latency side of financial application has moved to dedicated hardware close to the exchanges, FPGAs for execution and extremely high speed interconnects. The result of the rush for latency has been a lot of practical hardware and software which can transit datacenters in nanoseconds and provide real benefits to many application developers.
Directory Services
Traditionally the broker was responsible for message delivery, routing, and persistence. Moving to brokerless methods required splitting those out to separate systems, starting with service location. Producers and consumers would still need to know who and where to connect to. Separating this from the messaging system immediately simplified both components, into a directory service and message distribution system. The directory service could even be implemented on top of the message distribution, either with a simple look up to a service or a distributed protocol along the lines of DNS or BGP (the Border Gateway Protocol used in building internet router lookup tables).
In this model, as peers in the topology were started, they queried the directory service for which endpoints offered the data they required. Apps which could produce data registered their existence with the type (or topic) of data they provided. They then directly connected to the other parties required, or waited for incoming connections.
Using a form of distributed lookup protocol to spread the information improved fault tolerance over a centralised directory, and allowed a network to converge on proper locations without requiring the exact details of every part of the architecture to be known at startup. Local peers could locate and connect to a directory either through a reliable name, an external directory, such as DNS, or by a configuration perhaps from dedicated configuration management tool, which were often already used in large deployments.
Directory services also offered the chance to use messaging to describe changes to the directory. In traditional broker-based messaging systems there is often a difference between creating a topic over which messages may be sent and immediately sending a message with a just-in-time created topic. The difference generally resolves to the ability for the system to respond to the creation of a topic, and that is something which can be replicated in brokerless systems at the time of the creation of a topic within a directory service. Using topic creation as a signal point can be beneficial in signalling existing systems that a new data source may be available, for spinning up or allocating resources to handle the incoming streams of data, or other methods that modify the wider system configuration in response to the availability of data.
Some systems, such as OpenDDS from the OMG, combine an RPC (CORBA) based message passing library with a directory service: in this case the OpenDDS information repository. This service tracks the availability of resources and wires together brokerless components in order to handle message flows. Some systems use generic services such as Apache Zookeeper to accomplish the same result. By building these services in a message-like way, the systems can be designed to react to changes to ensure quality of service by distributing different endpoints to differently prioritised services, or to dynamically reroute based on newly available nodes or sources.
Flow Control
By the late 2000s brokerless messaging systems had expanded to include new variants from existing messaging players such as Reuters LLM (low latency messaging), who were eking out ever more speed by implementing their own networking protocols, and using speedups like kernel bypasses and RDMA, code optimisations and clever networking setups. For maximum performance, some systems worked over IPC (Interprocess Communication) type methods between processes on one machine, or even between threads inside a single process for parts of applications.
At the same time, the types of messaging consumer rapidly expanded to any manner of different devices with varying capabilities, in all sorts of locations: everything from locally connected high performance servers to distant mobile phones. This lead to a distinct pressure to be able to respond to wildly different capabilities from different types of consumers, but still reliably deliver information.
TCP is an excellent protocol, and the natural choice for reliably delivering data, but prioritises reliability over latency, and will degrade latency in cases of congestion or network issues. It also has certain built in requirements, such as delivering only in-order data. TCP senders are limited in how much can be sent before they receive an acknowledgement. This requirement means the sending rate is tied to the latency of delivery to the receiver - if, for whatever reason, it takes an acknowledgement from a receiver longer to arrive than before (perhaps network delay, or a delay in sending the ACK), the transfer rate is significantly reduced. If there is any actual loss of data, TCP will back off its transmission rate in order to avoid network congestion. This is a useful and practical design, but causes latency to be somewhat unpredictable, which is not always desired.
The internet protocol developers also created the User Datagram Protocol or UDP, which simply makes best effort to deliver its data. This means that if any packets are lost they wont be retransmitted. All UDP packets that arrive at an endpoint are delivered to the consuming application as soon as it is ready for them. This means data may arrive out of order, but it will be delivered as soon as it appears, which in some cases, and for small messages which are unlikely to be split across packets, may be preferable. It still leaves open the question of how to handle consumers that can accept data at different rates.
The idea of managing the stream of messages to consumers with different speeds and capabilities falls under the term flow control. It is performed at every layer from the messaging system down through the network stack. If there is a consumer who cannot consume incoming messages fast enough, that could potentially effect the producer. The producer has to slow down for the slowest consumer, and batch up data to send. Alternatively, it has to ignore the speed of its consumers, send as fast as it wants, and risk consumers missing packets. Finally, it can try to find some in-between option - usually through use of bounded queues. In the brokerless model, queues are more like intermediate buffers, with both sender and receiver having some degree of queuing support. They also tend to be invisible, part of the fabric of message delivery rather than explicitly part of the application.
The tricky thing is that buffers can hide the presence of bad consumption patterns, such as slow subscribers. If a single consumer is slow, the server side queue for it might slowly grow until eventually it consumes all the memory and causes the producer to fail, affecting all consumers. Measures like setting a high water mark or queue size limit can prevent a temporarily slow consumer from crashing the system, but doesn’t address the fundamental issue - at some point you either have to just ignore the slow consumer and drop messages intended for it, or queue more and more on the producer.
The choice often depends on the type of work being done, and the relationship between the consumers. Uncoordinated consumers will generally want to be at the full rate: for example consumers listening to a feed of news messages don’t want to get information later because one of their peers is slow. Coordinated consumers on the other hand generally want to slow down across the board - for example workers handling incoming job requests will all be impacted if one of their number crashes (as there will be less around to handle the load), so it’s beneficial to slow them all down and increase size of the backlog.
TCP supports a coordinated consumer model, by applying backpressure for individual connections. As senders can only send when a TCP receiver has acknowledged receipt of previous packets, the sender speed is receiver controlled. Simple backpressure can be propagated back through a network by having senders block, or refuse to send more messages, until messages have been transferred down the line.
UDP, on the other hand, does not have an acknowledgement, and the receiver will drop messages if it does not have space to handle them. The rate of send for UDP is sender controlled. However, in either case, on top of this networking infrastructure messaging systems often need their own flow control. The system may implement credit based flow control, much like the AMQP 1.0 flow control model (and not dissimilar to TCP sliding windows). In this method consumers first register credit with the producer, and the producer may only send to a consumer while it has credit remaining. This allows receiver controlled speed management, but at the level of individual messages rather than bytes of TCP buffer space. This gives more flexibility, but sometimes requires introducing more levels of configurability in order to provide good results.
A> One interesting property of queue management is the idea of a Low Water Mark. A High Water Mark is a maximum queue size - the buffer limit for the queue. Once this is hit, the system may drop or refuse any more messages until it has made some space, by the application or next hop consuming some. However, immediately opening the system up for more messages often provides rather poor performance - for example, it’s a bit of a lottery who might put a message in next, meaning one sender out of many could flood out others by just retrying a lot faster. It can also mean in the case of small messages that just one is being sent at a time, meaning a less efficient usage of the network. For that reason, some systems implement a Low Water Mark as well as a High Water Mark. Once the limit has been hit, a system will not accept messages until there is both space in the queue and the queue has shrunk to the size specified as the low water mark. This can lead to significantly more consistent and predictable performance.
Beyond the simple case of blocking the enqueueing of more messages, producers can try and manage their queues in more intelligent ways. The easiest option may be just dropping messages instead of blocking, if it can be reasonably assumed newer information will replace the data that is lost (for example with market price quotes, if you wait a little bit there’s almost certainly going to be a newer price coming in). Alternatively messages in the queue can be rolled up with similar messages - so that duplicate items are combined in to one, newer pieces of information supplant older ones and so on. Intelligent drops may allow dropping messages based on the priority of different types. Even the queues themselves may be split differently - per receiver, per topic, or some other measure, to allow better management of flow. All of this requires some understanding of what the messages represent, echoing the questions around message formats we saw earlier.
Persistence and Asynchrony
Handling failure and errors is part of the great challenge of distributed systems. A broker provides natural place for persistence, but in part because brokers bundle that functionality together with other systems it binds together very different requirements and stresses. Flexibility in choice of persistence, in levels of reliability and many other parameters are vital for effectively tuning messaging systems. Brokerless models, without a central node that will see all messages, require an alternative approach.
By separating storage and routing, the brokers’ traditional role of persisting messages can be moved to separate systems entirely. A simple store-and-forward queue could take messages, put them into a persistent store, and forward them on to any requesting consumer. The downside of this model is that it is easy to for the store to become a bottleneck - the speed is limited to the speed of storage on the device, and every message requires an extra network hop. By distributing this onto multiple intermediate devices, the load can be spread to whichever intermediary has the appropriate messages - so a receiver might receive one message from store A, another from store B, and hence improve the throughput (with acknowledgements flowing back similarly), but at the cost of a potential out-of-order message, or a need for reordering on the client.
The next evolution was to move the store out of the message path entirely, and to have messages stored in parallel with consumption, rather than in-between. This architecture, popularised by 29West’s UltraMessaging line of message systems (now part of Informatica), provided for simpler storage services, more flexibility for clustering and adding fault tolerance, and greater decoupling between distribution and persistence.
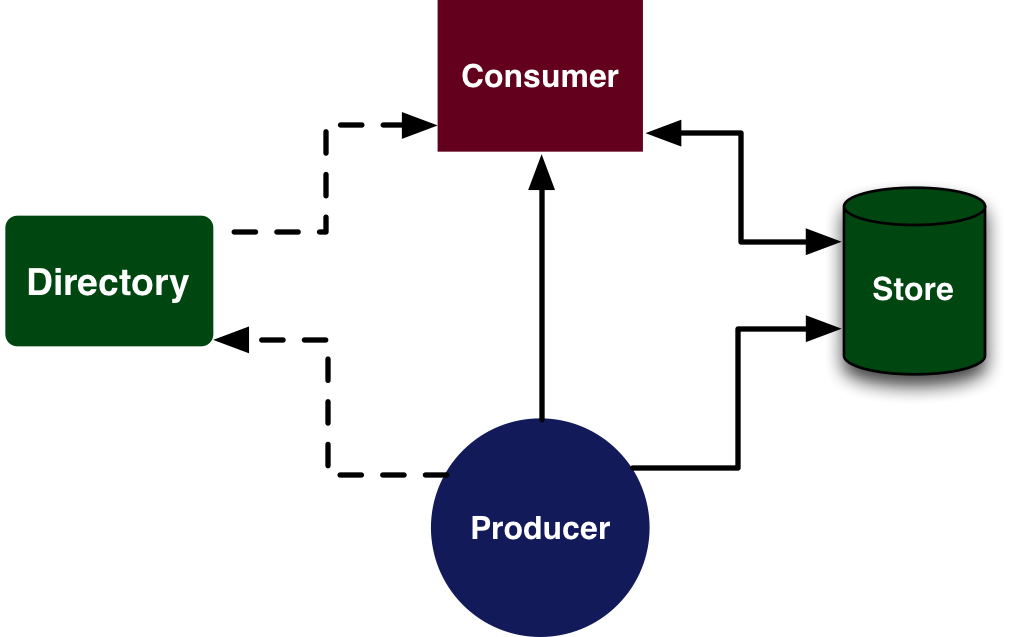
By using a Pub/Sub model, messages can be sent to both a consumer and a groups of stores, or a separate communication path can be established to feed the stores. Stores can send back acknowledgement of stored messages to the producer if required. This storage can be to any number of different devices, and rather than waiting for confirmation from every single store the producer can just wait until it has a quorum, or simple majority, of stores that have acknowledge receipt of the message. Each store itself is a simple device, managing a stream of incoming messages and occasional requests to replay that stream.
The exact same logic could be used for reliable consumption, by saving message receipt acknowledgements in a store, or the quorum of a set of stores. This handled the problem of longer-term asynchrony, so that services can come and go flexibly. Restart can be handled by querying the ACK stores for the last acknowledged state and asking the message stores to replay all unconfirmed messages. We could even address the late joiner problem with this, where a consumer that joins late either has to delay the early joiners, or miss the start of a feed of data.
Moving ACKs out of band in this way also doesn’t limit the feed to the speed that consumers can consume, but allows slow subscribers to pick up data directly from the stores at their own rate. In this case the producer is only limited by the speed at which the cluster of independent data stores can confirm writes. This generally scales up more predictably as more stores are added. For consumers that have crashed and need to recover, restarting and catching up is no different to any other slow consumption situation, as they could pull their state from the stores and quickly come up to speed.
This helps address the problem in brokerless systems of availability - in a broker based environment the broker (or broker cluster) was either up, and everything worked, or down, where it didn’t. Separating components means different parts may be failing or in recovery at different times, and good system design needs to take this into account. Of course, in both cases real world components fail in unpredictable and non-total ways (degrading performance say, or having brief, self-recoverable outages), which often require a similarly gradated response.
Multicast
Beyond UDP and TCP, messaging system developers also had the option of communication via multicast. This was originally used in messaging systems to distribute the broker itself, and eventually became an option for message distribution in brokerless systems, particularly under the Pub/Sub model.
The idea behind multicast is that, at some level, it was wasteful to have send a copy of each message specifically to each client. If you’re publishing data in New York and 10 traders are listening to that data in Chicago it is less than optimal to send that data 10 times down the NY-Chicago wires. That’s exactly what was happening though, as the protocols used were unicast - point to point. Various players, notably Tibco, Microsoft and network hardware giant Cisco, quickly identified that there was value in multicast, where a single copy was sent as far as it could be, meaning there was no unnecessary duplication, and much lower bandwidth usage for multiple consumers of message streams.
Multicast is a specific type of one to many communication, along with its cousin, broadcast. The difference is that while broadcast communications are sent to all machines on a network, multicast communications are sent to a specific subset who have registered their interest in receiving that communication. In IP multicast this is accomplished using multicast group addresses, an IP address from a range reserved for that purpose.
This, conceptually, is very similar to registering a pub/sub subscription, with very simple routing or filtering performed at the networking hardware level. Protocols such as IGMP, the Internet Group Management Protocol allow receivers to join and leave multicast groups, but importantly this isn’t communicating to the producer or sender of the multicast messages, but to the networking hardware in between: the routers and switches. This meant that the hardware could intelligently distribute data - in the New York to Chicago case, packets for a certain group would be sent once down the link, then distributed at the final point to the traders. Multicast routing effectively constructs a minimum spanning tree of the network, so that data is only sent where it is needed.
This was great, but multicast had problems of its own. As the producer didn’t know who was listening, it was hard to do reliable delivery - a consumer could miss a message, and the producer would never know. It was also hard to know whether a consumer was being overloaded with messages - multicast was more like UDP in being sender flow controlled: the producer could send at the speed it wanted and the consumer just had to keep up.
To overcome this, Tony Speakman at Cisco started working on a specification for a reliable multicast network protocol, initially called Pretty Good Multicast, which was quickly renamed to Pragmatic General Multicast or PGM. Tibco were early users of the system for minimising network usage in their TIB and Rendezvous products, and in 2000 released an open implementation. Talarian, another messaging middleware provider, contributed to the protocol and tooling, and after several years of improvements and refinements to the protocol from people like Todd Montgomery, and Jim Gemmell at Microsoft, the protocol was standardised as RFC3208. In 2006 Steven McCoy released the first version of OpenPGM, which bought open source support to many more platforms than before. Now supported by many messaging systems and a large range of network hardware, PGM provides powerful and flexible way of delivering messages from multiple producers to multiple consumers in a reliable way.
“PGM is best suited to those applications in which members may join and leave at any time, and that are either insensitive to unrecoverable data packet loss or are prepared to resort to application recovery in the event. Through its optional extensions, PGM provides specific mechanisms to support applications as disparate as stock and news updates, data conferencing, low-delay real-time video transfer, and bulk data transfer.”- PGM specification1
Under PGM, producers multicast ODATA messages out over a certain interface on their machine. Consumers receive these messages via the network as normal. Each message contains a sequence number - a sequentially increasing counter which allows receivers to spot gaps in the received messages. If a consumer determines it has lost a message, it will send a Negative Acknowledment back to the producer - effectively requesting the missed data. The producer, or a local designated repairer, will multicast the data required as an RDATA packet. To avoid loss of NAKs, producers will multicast NAK Confirmations (NCFs) when they receive NAKs, and if they don’t see a confirmation in time, consumers can resend their request.
The NAK cleverly flipped the acknowledgement on its head, assuming that the most messages were delivered reliably. When repair was required, the system also did not require that the original producer had to do it - other nodes around the network could supply the data if they had it, allowing smart architects to build systems where lost packets only had to be retransmitted from a point close to where they were lost. On top of this, PGM implemented a feature known as NAK suppression. When a PGM aware piece of networking hardware saw a NAK request for a packet, it would pass it upstream towards the source, and it would suppress any further requests for the same bit of data, ensuring the producer was not swamped in the case of a widely-missed piece of data.
“Another powerful feature of receiver initiated recovery schemes is that since it is the receiver’s responsibility for error recovery, each receiver can determine the level of reliability required, independent of other receivers, by simply not requesting retransmission of missed data.” – Joseph J Brandt2
Because multicast is sender flow controlled, PGM allows for rate regulation. Producers can be limited to a certain bytes per second pace at which they can send packets, and will automatically portion data out so as not to exceed that rate. Theoretically then, if consumers can handle the published rate, they should be able to keep up, giving an “in-between” type solution to the flow control problem.