

In a previous post I talked about some of the ideas that drove QUIC, but in this one I want to got a little more into how it actually works to get data from host to host. Again this is all from the notes I made looking through the source and spec - so always go to the code for the latest!
All networking is constructed as a series of layers - each layer defining its own mechanisms for reliability, name resolution and other fundamentals. Though QUIC is a single protocol, the layering is still present within it - an individual piece of app data (say a HTML page) will be encapsulated with several different layers of framing: the stream frame, the QUIC session, and a cryptographic channel.
This means any given QUIC packet can be peeled back. For example, a regular packet containing part of a web connection might look like: [[CRYPO HEADER] [ENCRYPTED DATA: [QUIC HEADER [STREAM FRAME HEADER [THE STUFF YOU ACTUALLY WANT]]]]]. While this looks like a lot of overhead, there are a few tricks that are used to minimise this, so in reality the headers will often be in the range of 20-30 bytes.
One of the fundamental decisions in QUIC is to multiplex streams over a single logical connection - much as SPDY multiplexes streams carrying web data across a single TCP connection. However, QUIC uses the connectionless UDP, so each packet is sent independently, without reference to some established connect. Therefore, the multiplexing needs to happen a little differently. QUIC creates what can be thought of as a cryptographically secured connection, or session, between a client and a server. Connection information and data packets are then sent without this logical pipe.
Every QUIC packet has some standard data included with it. An individual connection is identified by a GUID, a 64 byte pseudorandom number that is used to identify the connection. This is important, because the vagaries of UDP over the internet mean that the same connection between two parties may not consistently be on the same quad of (source, port, destination, port), which is how connections are normally identified. Each packet also contains a sequence number, which increments as each packet is sent (from either side), and it contains flags for whether the contents are FEC packets or data packets, and whether the connection is being reset. This forms the common QUIC packet header.
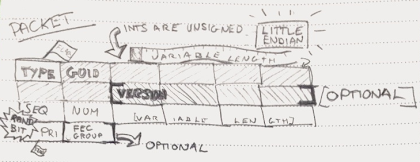
In case you wanted to see what my notes looked like
Both the GUID and sequence number can be sent in a reduced form - so if 1 byte is sufficient to identify the connection, or the number of the packet, we can set flags to indicate that, and save ourselves a bit of header overhead. There is a rough maximum packet size aimed for to avoid it being fragmented or split across multiple packets of the underlying communication layers (IP, ethernet, etc.). This is around 1500 bytes in most cases (though may vary when jumbo ethernet frames are present, or alternative lower layer protocols for the entire path).
Streams
Once the connection is established, either the client or the server can initiate a stream within it at any time. In most cases, one stream will be created at connection initialisation time by the requesting party (the client), to support the aims of 0-RTT where possible. In keeping with that goal, a stream is initiated simply by sending data with a 32bit stream ID which has not been used within the connection before.
To avoid collisions when creating new streams, streams initialised by the client start with an odd number and ones by the server with an even number. In either case, the numbers must always increase - it’s fine for the server to initiate stream 6 followed by stream 10, but not for it then to go back and initiate stream 8.
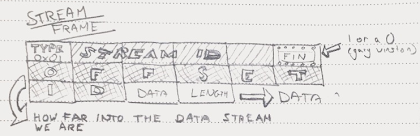
There are quite a few frame types which are used for different parts of the flow, but for streams we just need the type to be set to 1 for STREAM_FRAME. Once the type is established as a STREAM_FRAME, that defines the structure of the payload: a 32 bit stream ID, a byte currently used for sending a FIN flag to close the connection, a 64 bit offset to represent the byte position in the underlying data being sent, then 16 bits that describes the length of the remaining data in bytes. Generally, a given QUIC packet will contain data from only one stream, though as an optimisation small frames from multiple streams may be combined - in that case each will have its own stream header.
Proof of Ownership
One of the interesting ideas built into the QUIC protocol is the idea of proof. There are two areas where this applies: proof of ownership of an address, and proof of data received. Both of these are addressing specific threats that could be used for denial of service type attacks.
Proof of ownerships is a way for a QUIC server to validate that the client it is communicating with is really on the IP address that it appears to be - it’s easy to spoof a message from a certain IP, but harder to receive data sent to it without having a man-in-the-middle. To do this the server generates a hard-to-guess proof value, and sends it as part of the crypto packet framing along with some data. Receiving a valid value back from the IP indicates that the sender really is listening on that address. This is effectively how an unpredictable sequence number in TCP works, so is a familiar protection.
The other area of proof is in terms of received data. Some attacks involve tricking a server into resending data it has already sent, which often is significantly larger than the request to resend - so the server can be used to amplify a attack by causing a lot of extra traffic to be sent to a given host. So servers (though this works both way, its mostly a concern for servers) require proof that the user has received the data that has been sent thus far. To do this a specific bit is flipped randomly in the sequence number, and a flag is set in the QUIC packet header to indicate so. The receiver tracks a cumulative hash of the entropy seen so far, and sends that with ACK messages to prove it has really received the previously sent data.
Reliability

This leads on naturally to reliability. The first line of defence against packet loss is the Forward Error Correction mentioned in the last post, but QUIC also includes frame types for dealing with resending data, referred to as ACK frames (though they often represent a negative acknowledgement). The ACK frame in QUIC actually cleverly contains a lot of status information to allow the other side of the connection to have a clear understanding of the state. Unlike in TCP, ACKs don’t need to be sent all the time, but only as needed based on the congestion control rules.
As with all data frames, it starts with a type byte which in this case set to 2 for ACK frame. Then the remainder of the frame is split into two sections:
The first block shares information about sent data from this participant. This is a bit unusual! It means that in a client-server situation when the client acknowledges information it has received, it simultaneously communicates information about what has been sent to the server. This means that any ACK in either direction effectively updates the connection status between for both hosts. This is clever, and gives things like congestion control algorithms a lot more data to work with.
The block is structured as a byte for the hash of the entropy bits sent so far, to prove it has sent them. Next it the sequence number of the the first frame which has been sent, but has not yet been acknowledged.
The second block is structured the same way, but for data that has been received. The first byte is the entropy of frames received this far, and a sequence number of the highest (contiguous) packet received - so if 3, 4, 5, 7, 8 have been received, it would be 5. However, if there are less than 256 missing packets, the sequence number can instead be the highest received: in the previous case, 7. Then, the next byte is the number of missing packets followed by the individual sequence numbers of them. So, in this case the data would be [1] packet missing, [6] sequence number of missing packet.
This is a very cool optimisation - it means the ACK can function akin to a TCP acknowledgement, but can also operate as a NACK to ask for retransmission of specific packets that have been lost. This is particularly convenient for multiplexing if a packet is lost - valid streams can be ACKd and delivered while still requesting retransmission for the lost data.
Congestion Control
With the information in the ACK packets, each side of the connection has the ability to detect potential congestion on the path between them. In general, packet loss is the best sign of congestion as the two most common causes of packets being dropped (in a UDP scenario) are due to more packets arriving at a point than can be processed. If the receiving host cannot pull packets of the UDP buffers fast enough the kernel will likely just throw incoming data away. On the network, if a link is too busy the network hardware may drop packets. This can even happen if the network looks like it is about to become busy, or if systems like RED are enabled.
Unlike TCP, UDP has no native way of dealing with congestion. If a link between a client and server is congested, a TCP sender will back off and reduce the load until the connection stabilises. UDP has no way of detecting the failure though, so always sends at the full rate. This means that without other consideration, QUIC would overwhelm other protocols across a crowded link as the others backed off. It would take up an increasing amount of the available bandwidth, making it somewhat unpopular with network admins. Similarly, an overwhelmed receiver who was running out of memory would have no way to signal to the sender to reduce the flow.
QUIC offers two methods of congestion control, both designed to operate well on a primarily TCP network. These are signalled by another type of data frame called the Congestion Feedback Frame. Which type of congestion control is used is negotiated as part of connection establishment (it’s actually a tag which is communicated during the crypto setup).
The most straightforward type is a port of the TCP cubic congestion mechanism, as used in Linux. In this case the congestion frame has a type byte (3 for congestion feedback), followed 2 bytes for the count of lost packets, and then 4 bytes for the size of the receive window. This receive window determines how much data the other side can have “in flight” - meaning sent, but unacked. This data is used in the congestion control algorithm just like in standard TCP backoff - if three lost packets are seen, the window sized is halved, so the sender backs off. If the connection is going well, the window size can be increased, speeding up the rate of send. In QUICs case, it can actually communicate these changes to the other side with this frame type, while in TCP its generally implied.
The alternative system QUIC also supports is a pacing based congestion control. This is quite a different approach - rather than responding to dropped packets by reducing the send rate after the fact, the system attempts to estimate the bandwidth available and then measure out packets so as not to overwhelm the available resources. In a well functioning connection there should be a pretty steady back and forth of data and acknowledgements - if there is a delay in acknowledging then it is taking longer for that data to get through, which indicates extra buffering. Alternatively, if increasing the rate of send doesn’t result in a slowing of round trip, then there is extra available capacity, and sending can go faster.
QUIC can track the round trip time via ACK frames, but because each packet wont necessarily get an individual ACK it has a couple of other techniques. Firstly, it can track the time between different packets arriving. It uses this to estimate the available bandwidth (initially just by going with number of bytes sent / time). This is used to make a decision whether to increase the send rate, decrease it, or hold steady. It also provides an estimate on what state the connection is in - such as whether there is another flow it is competing with (which would result in more rapid changes to the congestion conditions).
Secondly, information is communicated explicitly in the congestion feedback frame, just as with the cubic congestion control implementation. In the pacing case the frame looks a little different: it has the type byte, a count of lost packets as before, but they followed followed by a series of sequence number and arrival time pairs for the last few received frames. This allows the other side to calculate a number of explicit round trip times at once, and update its bandwidth estimation more accurately.