Qwen-Image
September 29, 2025
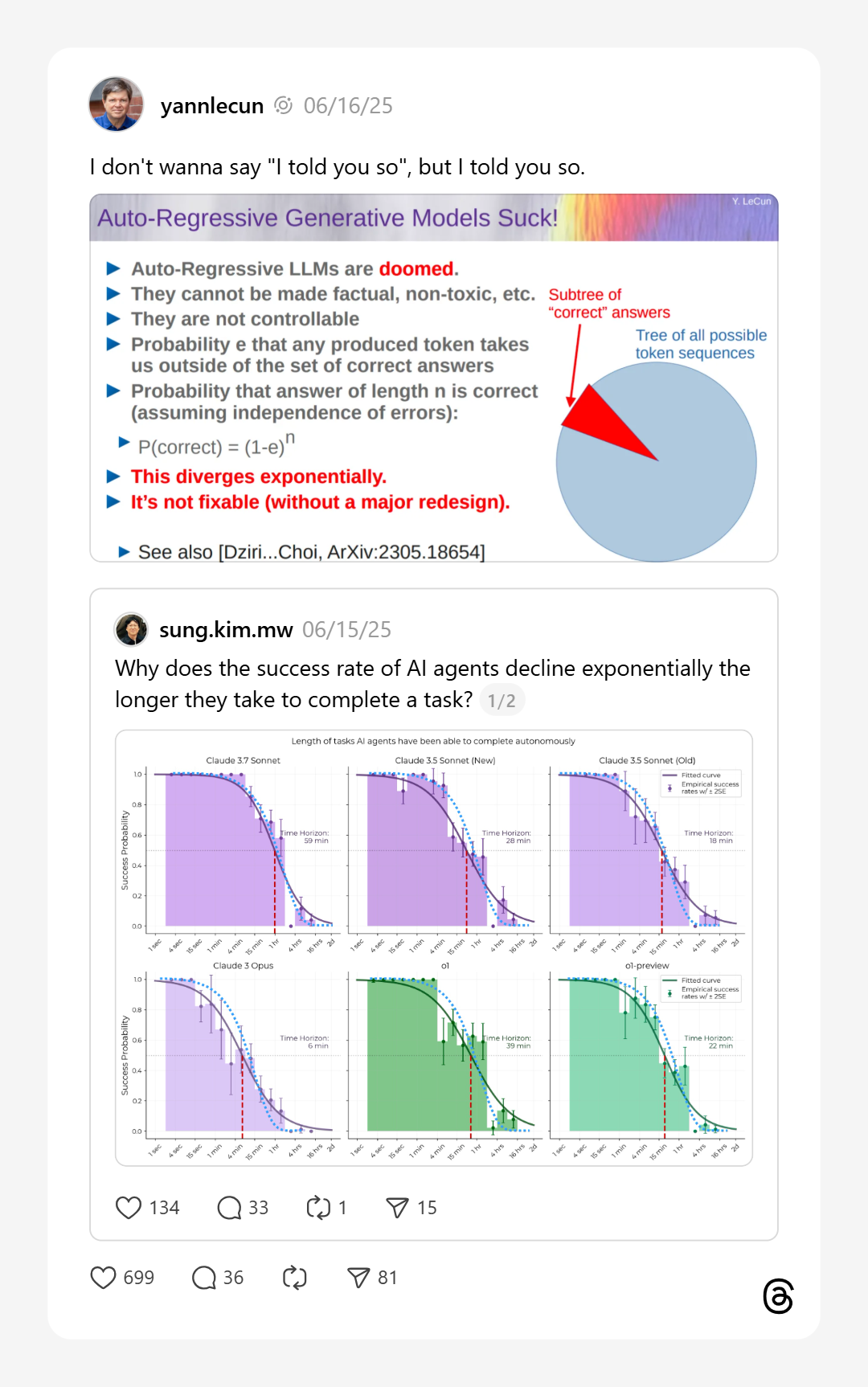
GPT4o’s image generation was a remarkable event, beyond the brief Ghiblification of all social media.GPT-4o offered significantly more steerability than earlier image generation models,, while offering image quality in the ball park of the best diffusion models. Qwen-Image gives a similar level of fidelity and accuracy and is an open-weights model with a pretty decent technical report: QwenLM/Qwen-Image.